Normalisierung
Normalisierung von Trefferzahlen in der Recherche
Sollen Suchergebnisse nach verschiedenen Attributwerten wie Jahr, Region oder Medium ausgewertet werden, so ist es unabdingbar, die absoluten Zählungsergebnisse aus der Suchmaschine zu normalisieren, um valide Ergebnisse zu erhalten. D.h. statt der absoluten Trefferzahlen sind unbedingt die relativen Trefferzahlen zu verwenden.
Bedienungshinweise für die aktuellen NoSke
Metadaten wie Jahr, Region und Medium werden in der Terminologie der NoSke text types genannt. In der aktuellen NoSke-Version ist es mittlerweile möglich, bei Frequenz-Auswertungen nach einem solchen text type die korrekt normalisierten Werte direkt anzeigen zu lassen. Dazu ist in der Anzeige eines Frequenz-Ergebnisses die Option „Relative Häufigkeiten anzeigen / Show relative in text type“ und/oder „Prozentualer Anteil an Konkordanzzeilen anzeigen / Relative density“ zu aktivieren.
Erstere liefert die Ergebnisse in i.p.m (instance per million oder auch hits per million). Die Relative Häugigkeit stellt die relative Verteilung der Ergebnisse als %-Satz dar.
Vgl. den Screenshot einer Auswertung des Begriffs „Haus“ nach doc.year im Demo-Korpus amc4_demo:
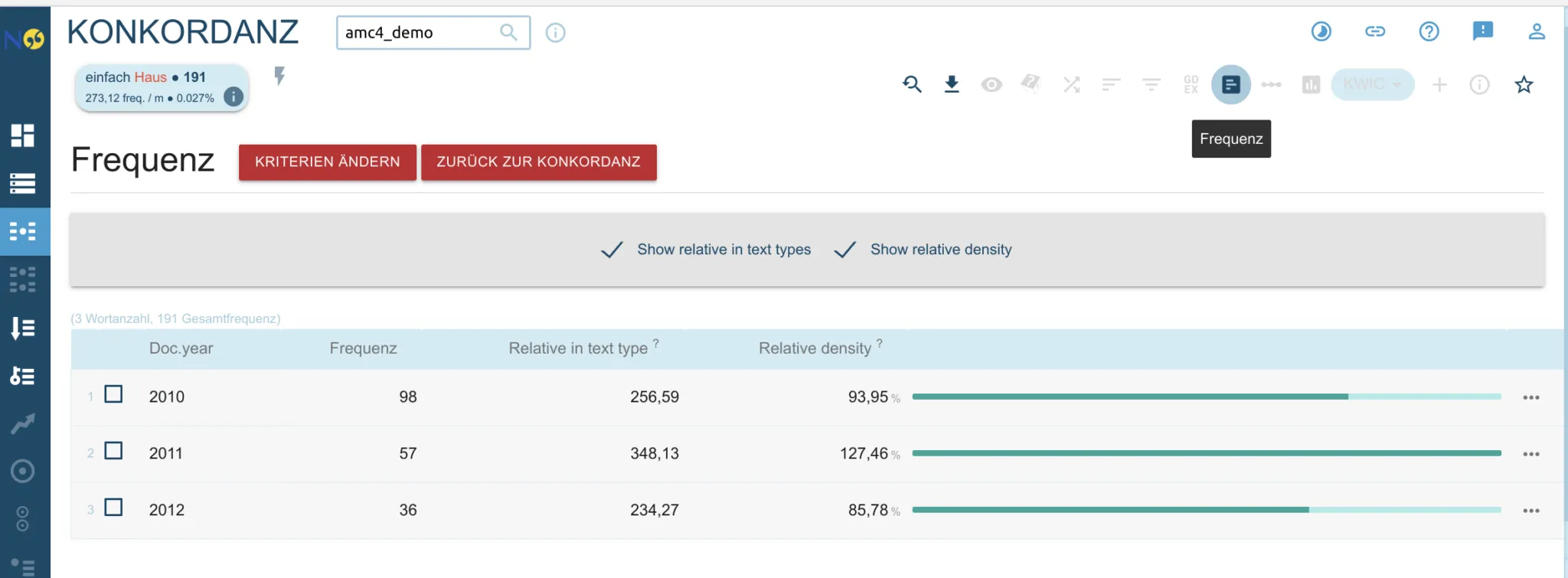
(Tip: Seit 2024 bietet die NoSketch-Engine übrigens für diese häufig nachgefragte Auswertung — Trefferzahlen über die Zeit — in der Werkzeugleiste rechts oben eine eigene Funktion namens „Der Zeitsstrahl“ / „Timeline“ an, die auch gleich eine grafisch ansprechendere Visualisierung produziert).
Bei der Frequenzauswertung nach einem einzelnen text type ist also aktuell eine nachträgliche manuelle Normalisierung nicht mehr notwendig. Diese bleibt aber weiterhin unverzichtbar, wenn gleichzeitig mehr als ein text type quantitativ ausgewertet werden soll. Also wenn z.B. die Verteilung von Treffern über doc.year und doc.region – also gleichzeitig über Zeit und Raum – verglichen werden soll.
Der Einfachheit halber wurden aber für die nachfolgende Erörterung der „Normalisierungsnotwendigkeit“ Beispiele mit lediglich einem text type beibehalten.
Zur Verständnis der Notwendigkeit eines Normalisierungsschrittes betrachte man z.B. die mengenmäßige Verteilung aller Artikel über die Jahre:
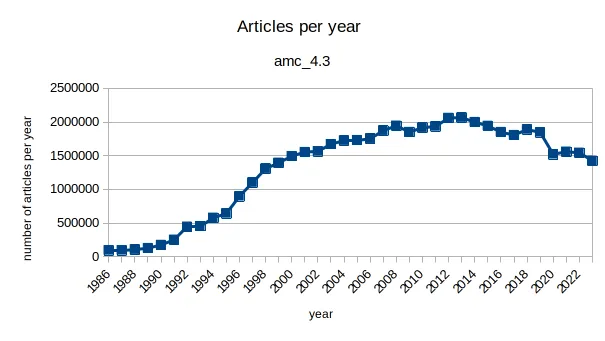
Es ist offensichtlich, dass ein Vergleich von absoluten Trefferzahlen für 1986 mit absoluten Trefferzahlen für 2018 nicht nur nicht „sinnvoll“, sondern grob irreführend ist, weil sich die Grundgesamtheit der Artikel in diesen Jahren stark voneinander unterscheidet.
Es muss daher vor einem Vergleich von Trefferzahlen für unterschiedliche Attributwerte immer eine Normalisierung stattfinden! Es dürfen also niemals „x Treffer (absolut) im Jahr 1986“ mit „y Treffer (absolut) im Jahr 2018“ verglichen werden, sondern der Vergleich muss auf einer relativen Trefferzahl für diese Jahre basieren.
Oder um ein reales Beispiel aus einem anderen Zusammenhang zu nehmen: es ist hoffentlich einleuchtend, dass der Vergleich der absoluten Fallzahlen für COVID-19 Infektionen zwischen sagen wir Liechtenstein (Einwohnerzahl ca. 39.000) und Indien (Einwohnerzahl ca. 1.4 Mrd) weitgehend sinnlos ist. Für einen aussagekräftigen Vergleich müssen immer normalisierte Zahlen (also z.B. „Anzahl der Infektionen pro 10 Mio Einwohner“) verwendet werden.
Ein in der Korpuslinguistik gängiges Maß für die Formulierung einer relative Trefferzahl ist z.B. Treffer pro Millionen Token (häufig abgekürzt als hpm – hits per million). Wie oben bereits erwähnt, liefern Frequenzauswertungen mit dem Korpustool NoSketch Engine bei Auswertungen für ein Attribut sowohl absolute als auch relative Frequenzwerte. Sollen aber Frequenzen für mehr als ein Attribut miteinander verglichen werden, muss die Berechnung der relativen Trefferzahl selbst vorgenommen werden! Ein ganz typischer Anwendungsfall sind Auswertungen der Auftretensfrequenz eines Begriffs sowohl über die Zeit als auch über Regionen.
Um die unabdingbare Normalisierung selbst durchführen zu können, ist das Wissen über die Größe der Grundgesamtheit in jeder der Unterkategorien nötig.
Für die tatsächliche Berechnung normalisierter Frequenzwerte steht unten für jede Korpus-Version eine Datei im Microsoft Excel-Format (xlsx) zum Download zur Verfügung.
Diese Datei enthält die Gesamtanzahl der vorhanden Token für jede Kombination aus docsrc (Medienname) region, year und — seit amc_4.3/2023 — auch yymm (d.h. Monate). Damit sind also die Grundgesamtheiten für alle üblicherweise verwendeten Facettierungen des Korpus verfügbar. Mit diesen Informationen kann die jeweilige Umrechnung der absoluten Trefferzahlen in relative, normalisierte Trefferzahlen z.B. in einem Tabellenkalkulationsprogramm vorgenommen werden.
| Korpus | xlsx zur Normalsierung (Downloadlink) |
|---|---|
| amc_4.24q3 | Download |
| amc_4.24q2 | Download |
| amc_4.24q1 | Download |
| amc_4.3 == amc_4.23q4LTS | Download |
| amc_4.2 | Download |
| amc_4.1 | Download |
| amc_3.2 | Download |
| amc_3.1 | Download |